






Azure Data Engineer Associate Certification C ...
- 2k Enrolled Learners
- Weekend
- Live Class
(550)
Most of us have an idea about who a data engineer is, but we are confused about the roles & responsibilities of Big Data Engineer. This ambiguity increases once we start mapping those roles & responsibilities with apt skill sets and finding the most effective and efficient learning path. But, don’t worry, you have landed at the right place. This “Big Data Engineer Skills” blog will help you understand the different responsibilities of a data engineer. Henceforward, I will map those responsibilities with the proper skill set & will guide you through the apt learning path.
Get a better understanding of the concepts and upgrade your skills from the Hadoop certification.
Let’s start by understanding who is a Data Engineer.
In simple words, Data Engineers are the ones who develops, constructs, tests & maintains the complete architecture of the large-scale processing system.
Next, let’s further drill down the job role of a Data Engineer.
The crucial tasks included in Data Engineer’s job role are:
 Designing, developing, constructing, installing, testing and maintaining the complete data management & processing systems.
Designing, developing, constructing, installing, testing and maintaining the complete data management & processing systems.The best way to become a Data Engineer si by getting the Azure Data Engineering certification. Next, I would like to address a very common confusion i.e., the difference between the data & big data engineer.
We are in the age of data revolution, where data is the fuel of the 21st century. Various data sources & numerous technologies have evolved over the last two decades, & the major ones are NoSQL databases & Big Data frameworks.
With the advent of Big Data in data management system, the Data Engineer now has to handle & manage Big Data, and their role has been upgraded to Big Data Engineer. Due to Big Data, the whole data management system is becoming more & more complex. So, now Big Data Engineer has to learn multiple Big Data frameworks & NoSQL databases, to create, design & manage the processing systems.
Advancing in this Big Data Engineer Skills blog, lets us know the responsibilities of a Big Data Engineer. This would help us to map the Data Engineer responsibilities with the required skill sets.
 Data ingestion means taking the data from the various sources & then ingesting it into the data lake. There are a variety of data sources with different formats & structure of data.
Data ingestion means taking the data from the various sources & then ingesting it into the data lake. There are a variety of data sources with different formats & structure of data.
Data Engineer needs skills to efficiently extract the data from a source, which can include different data ingestion approaches like batch & real-time extraction. There are various other skills which could make the data ingestion more efficient like incremental load, loading the data parallelly, etc.
When it comes to Big Data World, Data ingestion becomes more complex as the amount of data starts accelerating, & the data is also present in different formats. Data Engineer also needs to know data mining & different data ingestion APIs to capture & inject more data into data lake. The best way to become a Data Engineer si by getting the Azure Data Engineering Training in Washington.
 The data is always present in raw format which cannot be used directly. It needs to be converted from one format to other, or from one structure to another based on the use-case. Data transformation can be a simple or complex process depending on the variety of data sources, formats of data & the required output. This may include various tools & custom script in different languages depending on the complexity, structure, format & volume of the data.
The data is always present in raw format which cannot be used directly. It needs to be converted from one format to other, or from one structure to another based on the use-case. Data transformation can be a simple or complex process depending on the variety of data sources, formats of data & the required output. This may include various tools & custom script in different languages depending on the complexity, structure, format & volume of the data.

Building a system which is both scalable & efficient is a challenging work. Data Engineer needs to understand how to improve the performance of individual data pipeline & optimize the overall system.
Again when we are dealing with Big Data platforms the performance becomes a major factor. Big Data engineer needs to make sure that the complete process, from the query execution to visualizing the data through report & interactive dashboards should be optimized. This needs various concepts like partitioning, indexing, de-normalization, etc.
Apart from these, a variety of responsibilities can be found in Data Engineer job based on the tools & technologies which the industry is using.
Summarizing the responsibilities of a Big Data Engineer:
If you’ll look & compare different Big Data Data Engineer job descriptions, you’ll find most of the job description are based on modern tools & technologies from the Hadoop training in Chennai. Moving ahead in this Big Data Engineer skills blog, let’s look at the required skills that will get you hired as a Big Data Engineer.
There are a number of tools in the Hadoop Ecosystem which caters different purposes & professionals belonging to different backgrounds.
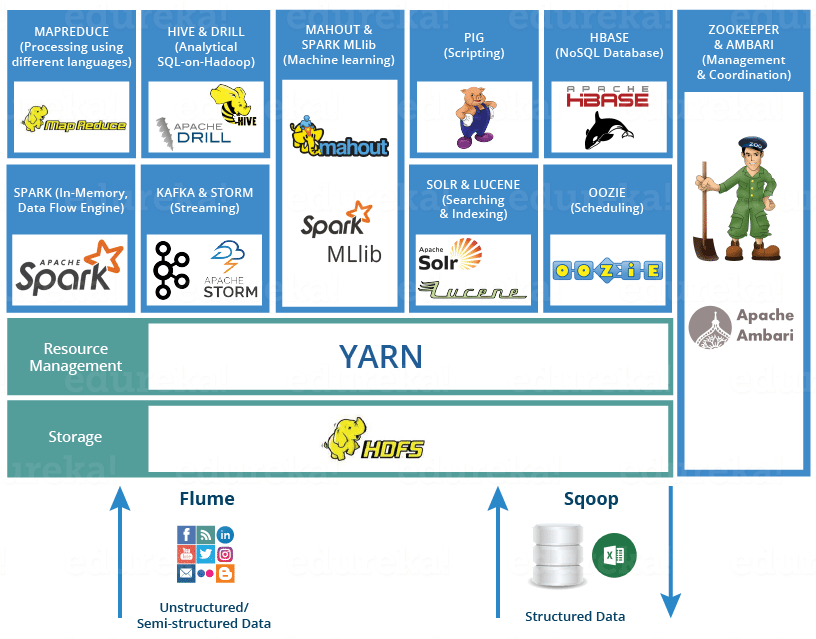 For a Big Data Engineer, mastering Big Data tools is a must. Some of the tools which you need to master are:
For a Big Data Engineer, mastering Big Data tools is a must. Some of the tools which you need to master are:
 Some of the most prominently used databases are:
Some of the most prominently used databases are:
HBase is column-oriented NoSQL database on top of HDFS which is good for scalable & distributed big data store. It is good for applications with optimized read & range based scan. It provides CP(Consistency & Partitioning) out of CAP.
Cassandra is a highly scalable database with incremental scalability. The best part of Cassandra is minimal administration and no single point of failure. It good for applications with fast & random, read & writes. It provides AP(Available & Partitioning) out of CAP.
MongoDB is a document-oriented NoSQL database which is schema-free, i.e. your schema can evolve as the application grows. It also gives full index support for high performance & replication for fault tolerance. It has a master-slave architecture & provides CP out of CAP. It is rigorously used by the web application & semi-structured data handling.
 Informatica & Talend are the two well-known tools used in the industry. Informatica & Talend Open Studio are Data Integration tools with ETL architecture. The major benefit of Talend is its support for the Big Data frameworks. I would recommend you to start with Talend because after this learning any DW tool will become a piece of cake for you.
Informatica & Talend are the two well-known tools used in the industry. Informatica & Talend Open Studio are Data Integration tools with ETL architecture. The major benefit of Talend is its support for the Big Data frameworks. I would recommend you to start with Talend because after this learning any DW tool will become a piece of cake for you.
Apart from the understanding of complete data flow & business model, one of the motivations behind becoming a Data Engineer is the salary.
The average salary for “Big Data Engineer” ranges from $94,944 to $126,138 as per indeed. Whereas according to Glassdoor, the national average salary for a Senior Data Engineer is $181,773 in the United States.
As of Nov 2019, the total number of jobs listed in renowned job portals are:
I hope this Big Data Engineer Skills blog has helped you in figuring out the right skill sets that you need to become a Big Data Engineer. In the next Big Data Resume blog, we will be focusing on how to make an attractive Big Data Engineer Resume which will get you hired.
If you are willing to upgrade your career & start your Big Data Engineer’s journey, begin with the Big Data Training in Hyderabad.







































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP









