






AWS Solutions Architect Certification Trainin ...
- 141k Enrolled Learners
- Weekend/Weekday
- Live Class
(56150)
AWS Data Pipeline Tutorial
With advancement in technologies & ease of connectivity, the amount of data getting generated is skyrocketing. Buried deep within this mountain of data is the “captive intelligence” that companies can use to expand and improve their business. Companies need to move, sort, filter, reformat, analyze, and report data in order to derive value from it. They might have to do this repetitively and at a rapid pace, to remain steadfast in the market. AWS Data Pipeline service by Amazon is the perfect solution. To learn more about Amazon Web Services, you can refer to the AWS Online Training.
Let’s take a look at the topics covered in this AWS Data Pipeline tutorial:
Data is growing exponentially and that too at a faster pace. Companies of all sizes are realizing that managing, processing, storing & migrating the data has become more complicated & time-consuming than in the past. So, listed below are some of the issues that companies are facing with ever increasing data:
![]() Bulk amount of Data: There is a lot of raw & unprocessed data. There are log files, demographic data, data collected from sensors, transaction histories & lot more.
Bulk amount of Data: There is a lot of raw & unprocessed data. There are log files, demographic data, data collected from sensors, transaction histories & lot more.
![]() Variety of formats: Data is available in multiple formats. Converting unstructured data to a compatible format is a complex & time-consuming task.
Variety of formats: Data is available in multiple formats. Converting unstructured data to a compatible format is a complex & time-consuming task.
![]() Different data stores: There are a variety of data storage options. Companies have their own data warehouse, cloud-based storage like Amazon S3, Amazon Relational Database Service(RDS) & database servers running on EC2 instances.
Different data stores: There are a variety of data storage options. Companies have their own data warehouse, cloud-based storage like Amazon S3, Amazon Relational Database Service(RDS) & database servers running on EC2 instances.
![]() Time-consuming & costly: Managing bulk of data is time-consuming & a very expensive. A lot of money is to be spent on transform, store & process data.
Time-consuming & costly: Managing bulk of data is time-consuming & a very expensive. A lot of money is to be spent on transform, store & process data.
All these factors make it more complex & challenging for companies to manage data on their own. This is where AWS Data Pipeline can be useful. It makes it easier for users to integrate data that is spread across multiple AWS services and analyze it from a single location. So, through this AWS Data Pipeline Tutorial lets explore Data Pipeline and its components.
 AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
With AWS Data Pipeline you can easily access data from the location where it is stored, transform & process it at scale, and efficiently transfer the results to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR. It allows you to create complex data processing workloads that are fault tolerant, repeatable, and highly available.
Now why choose AWS Data Pipeline?

So, with benefits out of the way, let’s take a look at different components of AWS Data Pipeline & how they work together to manage your data.
Check out our AWS Certification Training in Top Cities
AWS Data Pipeline is a web service that you can use to automate the movement and transformation of data. You can define data-driven workflows so that tasks can be dependent on the successful completion of previous tasks. You define the parameters of your data transformations and AWS Data Pipeline enforces the logic that you’ve set up.
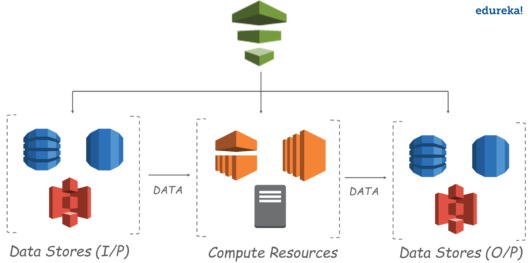
Basically, you always begin designing a pipeline by selecting the data nodes. Then data pipeline works with compute services to transform the data. Most of the time a lot of extra data is generated during this step. So optionally, you can have output data nodes, where the results of transforming the data can be stored & accessed from.
Data Nodes: In AWS Data Pipeline, a data node defines the location and type of data that a pipeline activity uses as input or output. It supports data nodes like:
Use Case: Collect data from different data sources, perform Amazon Elastic MapReduce(EMR) analysis & generate weekly reports.
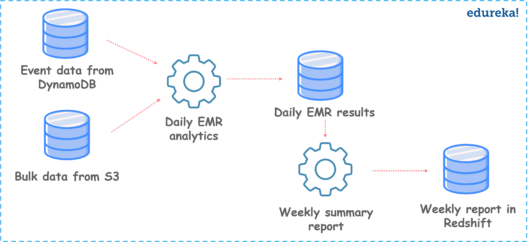
In this use case, we are designing a pipeline to extract data from data sources like Amazon S3 & DynamoDB to perform EMR analysis daily & generate weekly reports on data.
Now the words that I italicized are called activities. Optionally, for these activities to run we can add preconditions.
Activities: An activity is a pipeline component that defines the work to perform on schedule using a computational resource and typically input and output data nodes. Examples of activities are:
Preconditions: A precondition is a pipeline component containing conditional statements that must be true before an activity can run.
Resources: A resource is a computational resource that performs the work that a pipeline activity specifies.
Finally, we have a component called actions.
Actions: Actions are steps that a pipeline component takes when certain events occur, such as success, failure, or late activities.
Now that you have the basic idea of AWS Data Pipeline & its components, let’s see how it works.
You can even check out the details of Migrating to AWS with the AWS Cloud Migration Certification.
In this demo part of AWS Data Pipeline Tutorial article, we are going to see how to copy the contents of a DynamoDB table to S3 Bucket. AWS Data Pipeline triggers an action to launch EMR cluster with multiple EC2 instances(make sure to terminate them after you are done to avoid charges). EMR cluster picks up the data from dynamoDB and writes to S3 bucket.
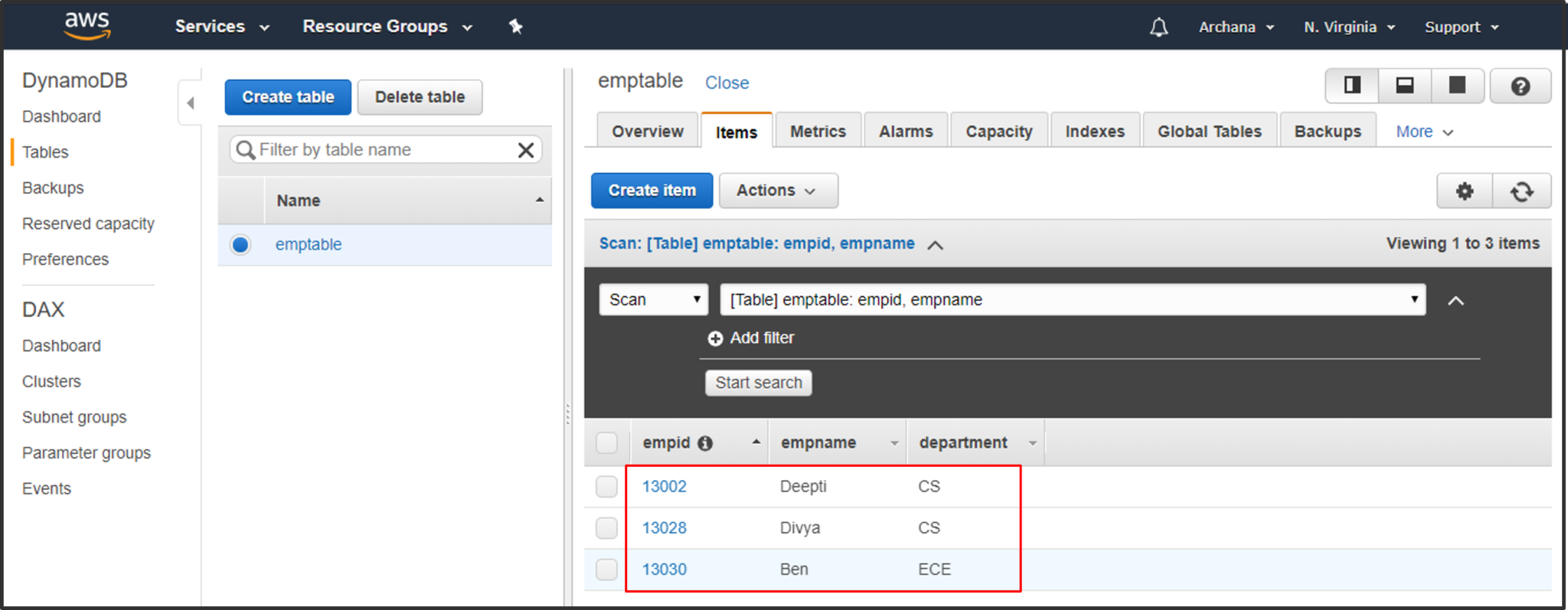
Step1: Create a DynamoDB table with sample test data.
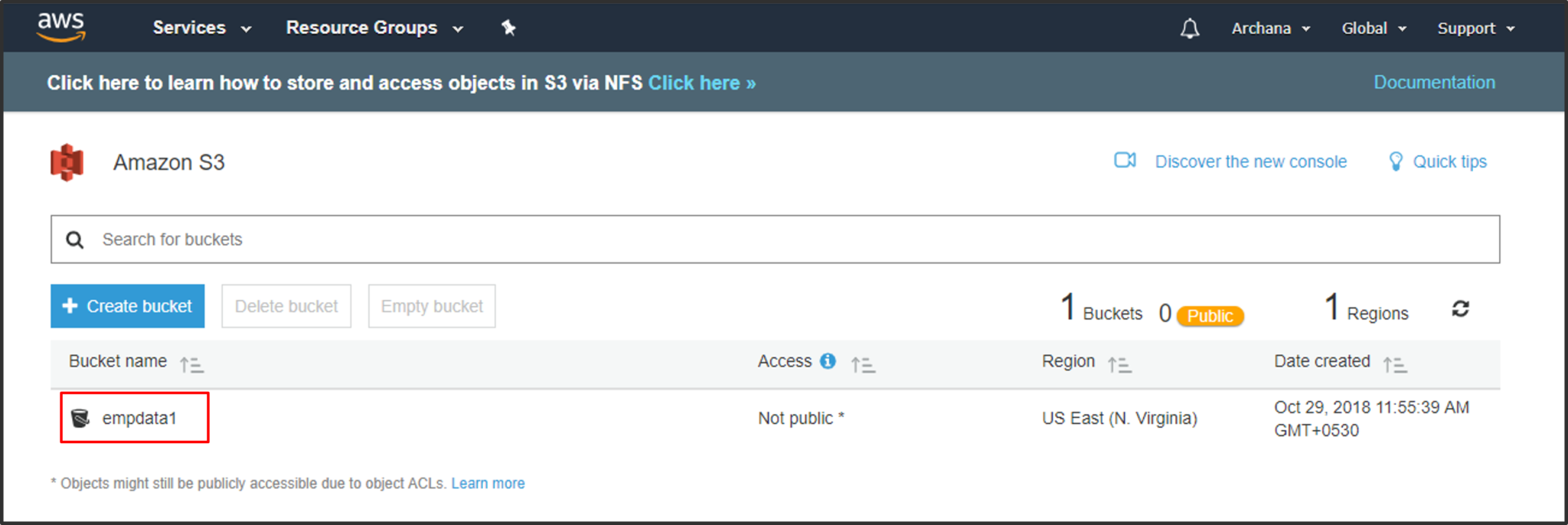
Step2: Create a S3 bucket for the DynamoDB table’s data to be copied.
Step3: Access the AWS Data Pipeline console from your AWS Management Console & click on Get Started to create a data pipeline.

Step4: Create a data pipeline. Give your pipeline a suitable name & appropriate description. Specify source & destination data node paths. Schedule your data pipeine & click on activate.
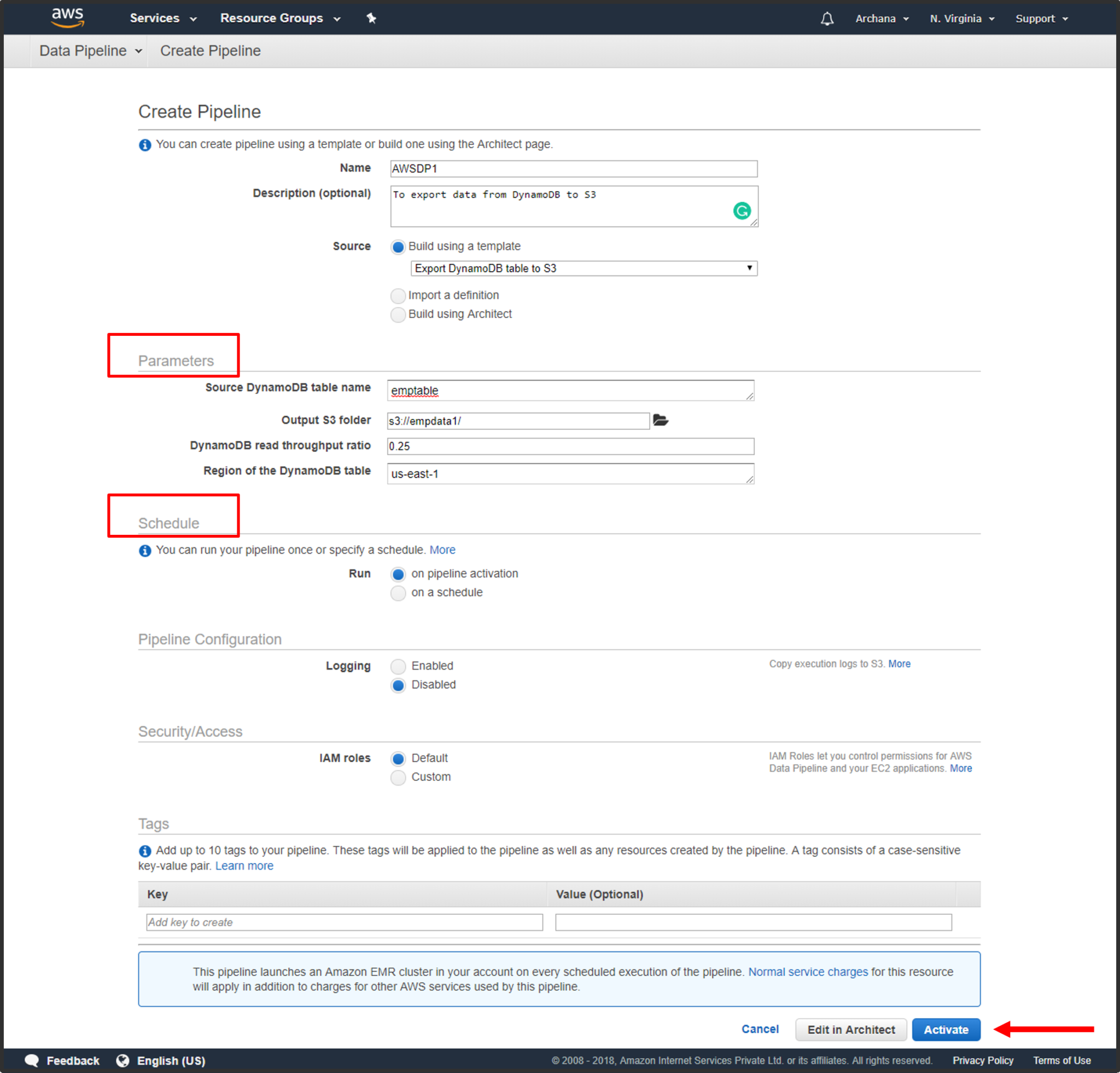
Step5: In the List Pipelines you can see the status as “WAITING FOR RUNNER”.
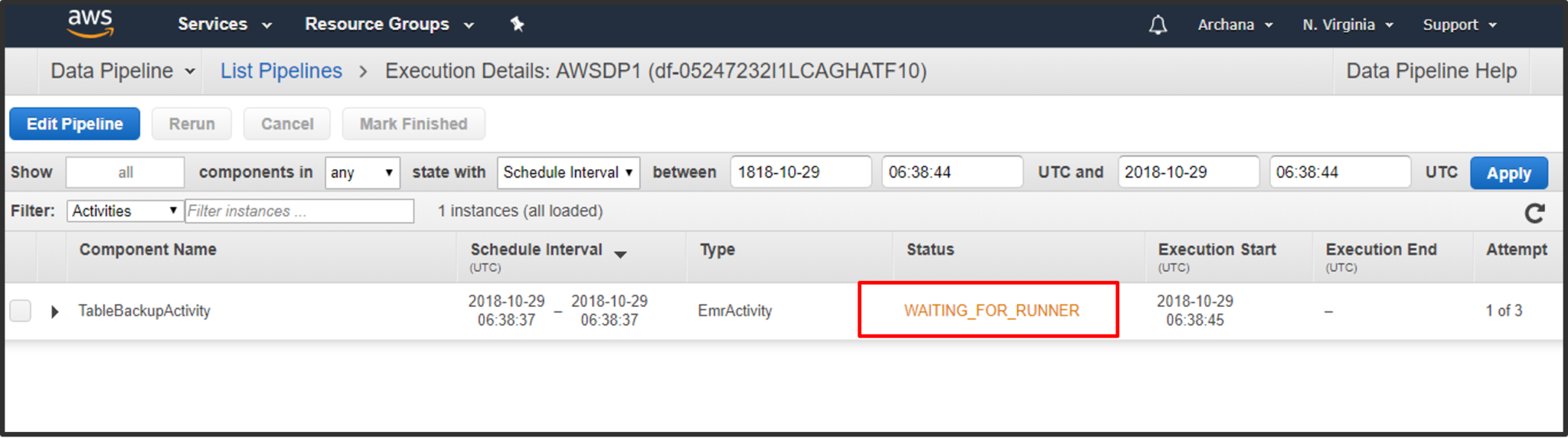
Step6: After a few minutes you can see the status has again changed to “RUNNING”. At this point, if you go to EC2 console, you can see two new instances created automatically. This is because of the EMR cluster triggered by Pipeline.
Step7: After finishing, you can access S3 bucket and find out if the .txt file is created. It contains the DynamoDB table’s contents. Download it an open in a text editor.
So, now you know how to use AWS Data Pipeline to export data from DynamoDB. Similarly, by reversing source & destination you can import data to DynamoDB from S3.
Go ahead and explore!
So this is it! I hope this AWS Data Pipeline Tutorial was informative and added value to your knowledge. If you are interested to take your knowledge on Amazon Web Services to the next level then enroll for the AWS Training in San Jose by Edureka.
Got a question for us? Please mention it in the comments section of “AWS Data Pipeline” and we will get back to you.
| Course Name | Date | |
|---|---|---|
| AWS Solutions Architect Certification Training Course | Class Starts on 28th January,2023 28th January SAT&SUN (Weekend Batch) | View Details |
| AWS Solutions Architect Certification Training Course | Class Starts on 30th January,2023 30th January MON-FRI (Weekday Batch) | View Details |
| AWS Solutions Architect Certification Training Course | Class Starts on 25th February,2023 25th February SAT&SUN (Weekend Batch) | View Details |































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP









